Installation - Software & OS Configuration

Introduction
This section has four parts: analysis server, storage servers, general/compression servers, and network.
Analysis Server Configuration
CPU
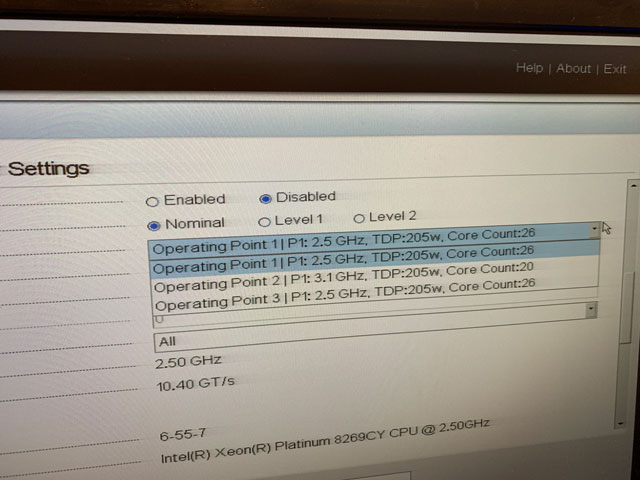
8269CY has two configuration, one 26 core @2.5G and one 20 core @3.1G. Our proposed pipeline is multi-threaded, so more cores should be better. I choose to run the CPU in 26 core @ 2.5G.
Disk Array
The analysis servers are responsible for processing data, not storing it. Therefore, data will first need to be fetched from the storage nodes and then saved back to storage after processing. Since the data size for each job can be different, we have to configure the disk array.
Based on previous estimations, we need high performance and capacity. On the other hand, we don't need that much of reliability. As a result, a RAID 0 array was chosen. For any production server, using 6 SSDs for a single RAID 0 array is a really bad practice. However, since we can easily recover from disk failure without interrupting the analysis progress (all data was stored on the storage backend), RAID 0 is the ideal solution for us.
Our R740 was equipped with DELL PERC H740P raid card, and raid 0 was configured.
Operating System
Our analysis server needs to run 7/24 with high reliability and throughput. Based on my past experience, Windows systems are somehow limited in terms of throughput compared to Linux. Also, Windows is less stable than Linux in most cases.
In terms of Linux, I'm familiar with CentOS/RHEL or Debian/Ubuntu. CentOS/RHEL should be more stable than Debian/Ubuntu but usually shipped with outdated system libraries or dependencies, which could be time-consuming to solve. Ubuntu, on the other hand, contains too many unnecessary components as a stable server system. Therefore, I choose to use Debian 10 as the OS.

Software / Dependencies
I use Python to write analysis pipelines, so Python 3 is required. In order to run the analysis pipeline, fastqc, salmon, trim_galore, and reference genes need to be installed or downloaded.
Storage Server
Disk Array
The top priority for storage servers is data safety, on the hardware level. In order to maximize disk utilization and performance, we need to configure an array with redundancy. The commonly used array configuration that provides redundancy are: RAID1, 5, 6, 10.
| RAID | Min Drives | Read/Write Performance | Capacity Utilization | Fault Tolerance |
|---|---|---|---|---|
| 1 | 2 | High/Medium | 1 Drive | Until Last Drive |
| 5 | 3 | High/Low | N-1 Drives | One-Drive Failure |
| 6 | 4 | High/Low | N-2 Drives | Two-Drive Failure |
| 10 | 4 | High/Medium | N/2 Drives | One-Drive Failure per Sub Array |
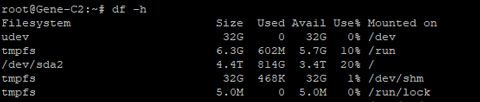
We have 11 disks from the same batch. Therefore, it is likely to have multiple drive failures at the same time near its end of life. RAID 5 apparently cannot provide enough security. RAIN 10, on the other hand, requires an even number of drives, and cannot perfectly tolerate 50% drive failure with a 50% capacity. In the end, RAID 6 was selected due to its balance between data safety, capacity, and performance.
Operating System
Not only me but other staff will be using storage servers, which makes a full-command-line environment less practical. Additionally, I plan to use Microsfot's Active Directory for centralized management, which makes Windows Server our choice. (After a year of running, I have to say Windows can be really bad as a storage server. I often had file(s) that I wasn't able to delete until the next reboot, which is not acceptable to a central 60TB storage server). Windows Server 2019 was deployed.

Performance Tests
Once the virtual drive was formatted, I performed a performance test. Given the cache size of the controller is 4GB, I chose to run a 10GB test to find out the true performance.
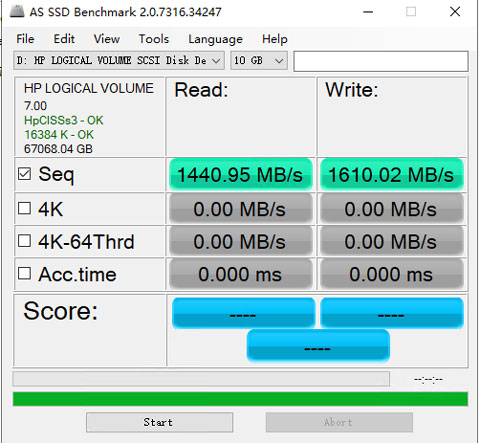
As we can see from above, the virtual drive has an R/W speed of 1440MB/s and 1610MB/s. This should be suffice for now.
OS Tuning (RDMA/RoCE)
By default, network share under Windows requires the CPU to process the outgoing or incoming traffic. Since the single-core frequency for our storage is relatively low, it will become the bottleneck on our 40Gbps link. Therefore, we need to configure RDMA to bypass the CPU while accessing the file. Ethernet is currently running instead of Infiniband, so RDMA over Coveraged Ethernet(RoCE) was configured.

Compression/General Server Configuration
Disk Array
Due to the same reason as the analysis server, RAID 0 was configured for our 6 SSDs. Again, this is really bad practice in most production environments, and most users should avoid this configuration.
Operating System
Since we need to run various of software for multiple users, Windows is the only choice for its GUI. Therefore, the same Windows Server 2019 as the storage server was installed.
OS Tuning (RDMA/RoCE)
RDMA requires both ends to be configured for it to work, so I applied the same RDMA configuration as the storage server.
Network
Core Switch
All bare-metal servers were connected directly to the core switch using MPO 12-core fiber. Among the 32 40G ports, 8 of them cannot be split into 4*10G ports, and I use these ports first to connect to the server. Then, I picked another port, set it to work in 4 * 10G mode, and then configured link aggregation on the port group. This will be the "uplink" to our 10G switch.
10G Switch
I configured link aggregation for the only 4 * 10G SFP+ ports, which will be the uplink to the core switch.

