Storage - Logical Volume

Introduction
The data size per day is not fixed. Since we want to store data in a unit of accession, and accession size could be different a lot, we need a new strategy to maximize tape utilization.
This section has two parts: tape replacement and logical volume.
Tape Replacement
The replacement of each tape takes a while. The tape needs to be unloaded from the system first, and then from the drive. A new tape needs to be loaded into the drive, formatted, and mounted in the OS. I couldn't see any easy way to do this automatically (I'm sure there is), and we still need human interactions for this part. Therefore, we should try to fully utilize a tape each time it is loaded. That is, we don't want to wait for 5 hours to fill the previous tape, replace the tape, and then copy the rest of the data. This is not practical in reality since it is hard to estimate copying time. Furthermore, the library can only host 23 tapes, and we need to manually replace those tapes on-site every month, which is an additional human labor that cannot be bypassed.

Since servers were connected using a 40G fast network, transferring from a remote location won't degrade the performance much, and storage servers can be used as a buffer. The data will be copied to the tape only after there is over 2 TB of data waiting to be stored.
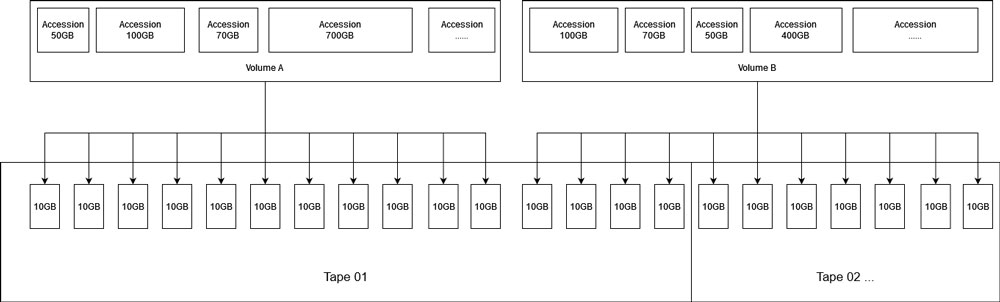
Logical Volume
In order to make sure all space on tape was used, data needs to be split into blocks of the same size.
Block Size
The bigger each block is, the variation in the size of the tail (last block) is larger. The tail size is non-standard, so we try to minimize the size of the tail. Given the capacity of the tape ranges from 2.10 TB to 2.15 TB, I choose 10GB (0.01TB) as the block size. In this case, even if the tail is only 0.1KB, we will be wasting about 10GB per tape in the worst case, which is acceptable. If we use a smaller block size like 1GB, it will become significantly more difficult to manage.
Strategy
While data is being compressed, it will be split into 10GB of block size. The compressed data for the entire batch is a logical volume. Each volume should contain about 225 blocks. These blocks could be stored separately in different tapes. It is difficult to have the size of each volume equal exactly to the capacity of the tape. Therefore, if the previous tape has a few more GBs, part of the current volume can be stored in that tape to maximize storage efficiency. In order to track where each volume is stored and which volume each accession is in, we need identifiers and databases. This will be discussed further on the next page.