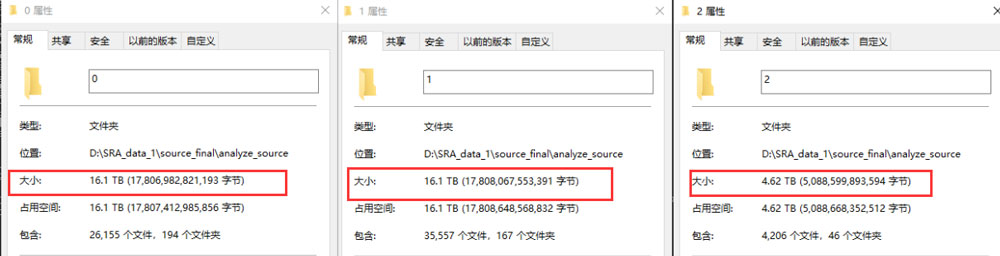
Data Process - Assigning Tasks to Queue
Introduction
Once data is downloaded, it has to be assigned to the analysis queue. Since each server can process file at different speed, and also account for future analysis server that has a different configuration, the script that handles the task assigning has to be "smart enough".
Task
We assume the speed at which each file was processed is directly proportional to its file size. However, there is no guarantee that this is true. Based on factors like server load or transferring time, the amount of data that each server processes can be different a lot. In addition, it is possible for us to assign additional analysis servers during peak time, or change the existing server for whatever reason. It is obvious that I cannot assign tasks by hand, and it is necessary to have a script handling this task.
The task is to come up with a design that can assign accessions to different servers based on pre-set multipliers.
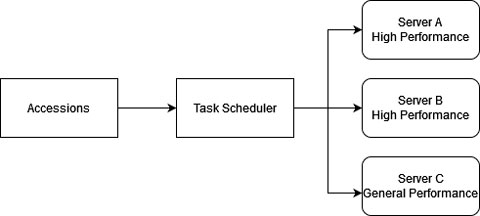
The Idea
Almost all the common algorithms for task assigning assumes each node is processing at the same speed. Therefore, before any algorithm can be applied, I have to apply multipliers to each configuration. Take a general DELL R630 with dual E5-2650v4 as the control group, and based on the hardware configuration of each server, I can estimate the amount of speed difference between each server.
Assume server A is 3.7x faster than the control group, then the calculated amount of data assigned to it will be divided by 3.7. That is when calculating the total amount of data assigned to server A, total size = actual size / 3.7. The actual size assigned to the server is not changed, but the size used to assign jobs was divided. This will balance the performance difference to some degree. Then, we can apply any load-balancing algorithm we want.
The Algorithm - Longest-Processing-Time-First
The algorithm I selected is the longest processing time (LPT) algorithm. This is a simple yet effective algorithm for job scheduling. Also, given the file size for different accessions can differ a lot (some hundreds of MBs and some over 4 TBs), assigning the largest job at last may overload a single node too much. Therefore, assigning the largest one first would be ideal.
Outcome
I was amazed by the algorithm's performance. While assigning tasks to one general-performance server and two high-performance servers (each of them 3.5x faster than the general one) together, the algorithm evenly distributes the workload as 4.62TB, 16.1 TB, and 16.1TB.