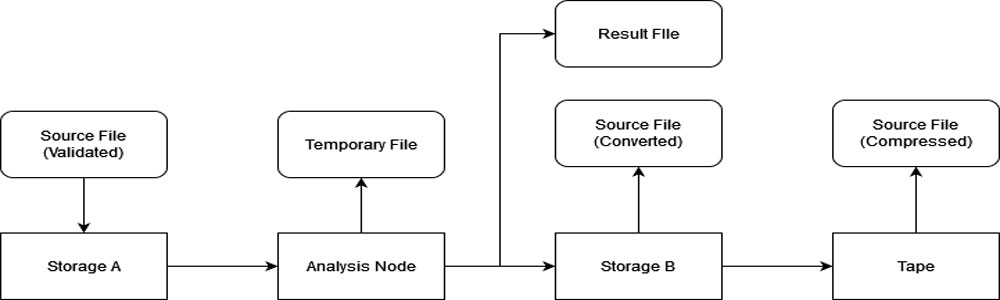
Pipeline - File Structure
Introduction
500GB - 700GB per day is a large amount of data, and I need to consider file structure carefully to maximize performance and data security.
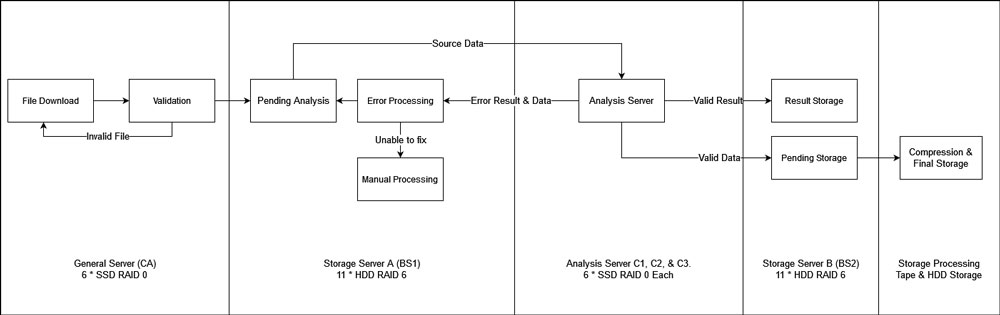
File Structure
Before assigning files to servers, I need to think of a few limitations.
The first one is the result. Analysis result is crucial and therefore should be stored separately to avoid potential disk problem due to drive failure or insufficient free space.
The second one is disk performance. Even in a RAID 6 array, HDDs can not provide good performance while reading and writing at the same time, and we should avoid reading and writing to the same server as much as we can.
The third one is validating data. This process involves compressing/decompressing multiple archives at the same time, so the disk needs to be fast and large enough. Also, we want to maximize the transfer efficiency, where the invalid files should be detected before moving to another location..
Therefore, the following file structure was designed as follows: