Data Analysis - Automation
We have to put a significant amount of human labor into data downloading, so we have to make the analysis pipeline automatically to reduce our workload.
This section has three components: task assignment, automated analysis, and error processing & storage.

Task Assignment
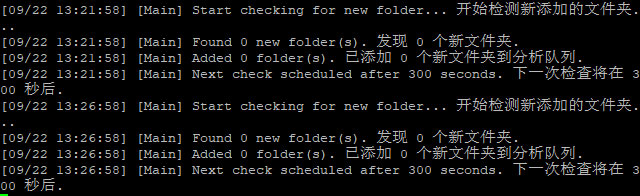
I choose to use the longest-processing-first scheduling algorithm, but how the newcomers actually enter the process queue without interrupting the current job could be an issue. In the end, I decided to create a dedicated directory for each analysis server as their queue. The task scheduler will only add data to the corresponding directory. This directory will be mounted on the analysis nodes, and the master scheduler on the analysis server will scan the directory and take over from there.
Sample run of task assignment. The scripts' messages were not written in English as I'm not the only user.

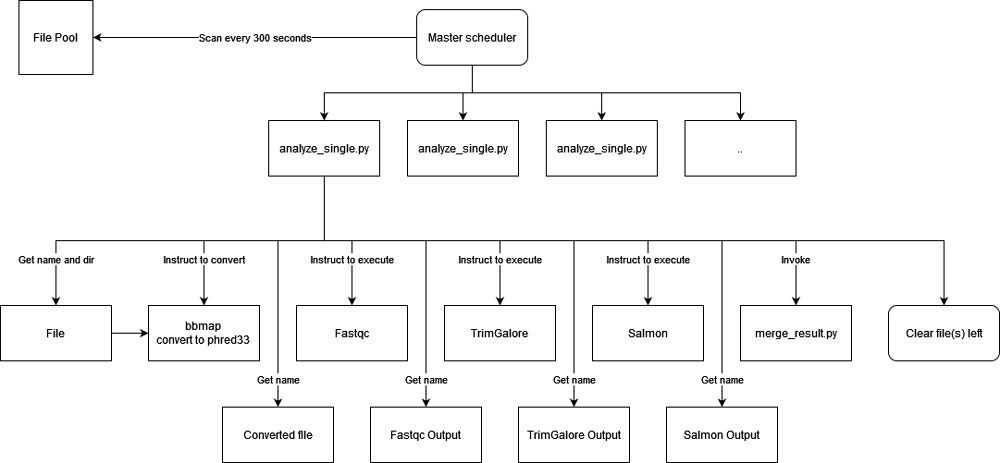
On the analysis server, I have separated the task into two parts: the master scheduler and the script executor. The master scheduler will create a pool with a maximum of 17 workers. The master scheduler will also scan the source directory for new files every 5 minutes. If any new file(s) is detected, it will be added to the pool automatically.
The script executor, on the other hand, is responsible for the analysis of each file. It will also be responsible for cleaning the residual generated during or left after analysis, even during a crash. That is, if an analysis script was executed and the next worker was invoked, there should be nothing left on the server from the previous file, no matter the result.
Automated Analysis
The analysis pipeline was fixed in the analysis script. At each stage, the input and out file has its own predictable format which the script can take advantage of. This makes it almost impossible to change the pipeline later. However, we are unlikely to change it anymore, and I have added a lot of customizable options and parameters in the config so I don't have to look into the code to make minor changes.
Once the analysis is finished, merge_result.py will be invoked towards the current accession automatically. This script will merge the result and move it to the final destination, or move the corresponding file to the error directory if any error marker was detected. The script will wait for the converted source file to be transferred to server B if necessary. After that, the temporary local file(s) will be wiped, and the scheduler will call the next worker.
Error Processing & Storage
Error Processing
Error processing cannot be automated, or fully automated to be specific. Since error is an unexpected situation, we couldn't prepare for it in advance. Thus it will require time to transfer files to the error directory. If we have an automated script that scans this directory every few minutes and starts to process new files when they haven't actually finished transferring, it could be a problem.
Luckily, server A is large enough to host those error files, and the error processing script can also finish all the tasks automatically once called. All we have to do is call the script with one click once every few days, which is not a significant time-consuming task. To make this process easier, a lot of other work(i.e. wrapper & helper scripts) has been done to facilitate manual actions which will be discussed in a later section.
Storage
There is much more to consider when dealing with storage, especially tape library, and it could only be semi-automated. Storage will be discussed in the next section.
Performance
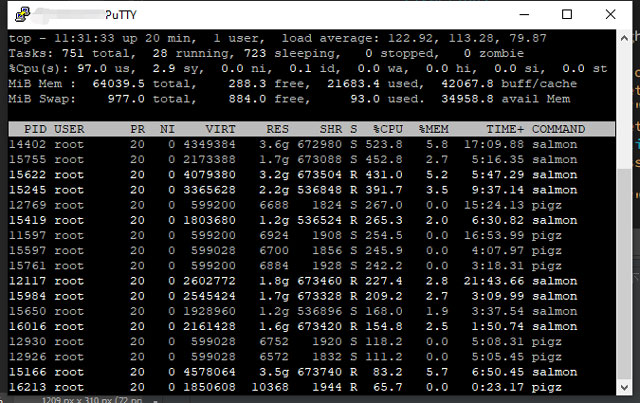
Once the pipeline was deployed, the CPU was continuously fully loaded at above 95% utilization when there were enough pending tasks.
Navigate through the Data Analysis Section
- Prev
- Overview
- Software & Structure
- Optimization & Performance Improvement
- Dealing with Errors
- Result Collection
- Automation
- Next